
Would the main version of the page please stand up?
What does Canonical mean?
The literal definition of canonical comes from religious rhetoric and originally referred to a set of sacred books that were accepted as genuine or preferred.
A good way to relate this to the modern, digital world is when a celebrity is verified on Twitter with that little blue tick next to their names.
No, this isn’t solely a way of further boosting their ego’s (although I’m sure they love it!) it’s actually to differentiate from other people / companies of the same name or users who try to impersonate them.
It’s pretty useful…
Now think of pages on your website that may serve duplicate content or highly similar content.
How does Google know which is the main one?
You need to let them know.
Google themselves say that if you don’t explicitly tell them which URL is the canonical they will decide for themselves, which can potentially be harmful for your SEO and rankings in Google.
What is a Canonical tag?
The Canonical tag is a HTML element that you add to a webpage to tell Google which page is the canonical (priority).
It typically looks something like this:
<link rel=”canonical” href=”http://www.limelightdigital.co.uk/” />
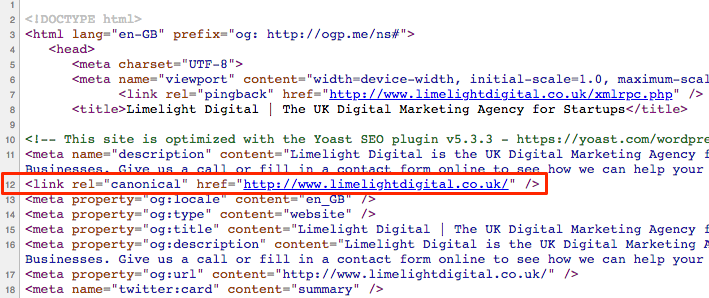
As you can see the tag itself is rel=canonical and a canonical tag is often referred to by this name or sometimes even ‘canonical link element.’
As we know, canonicalisation has been around for a long time but the rel=canonical tag itself came out in 2009 and was brought in by Google to stop legitimate duplicate content from affecting websites
Not only does this work for an individual site, but canonical tags can also work across domains.
An example of why the same content might appear legitimately across two domains is a site migration.
In this case you should paste the following line of code into the header of your old site’s page to let Google know that you know want them to prioritise newwebsite.co.uk’s content.:
<link rel=”canonical” href=”http://www.newwebsite.co.uk/” />
How are Canonical Tags implemented?
As touched on earlier, you simply need to paste the tag that describes the desired canonical page into the header of each of the pages you want this to refer to.
So for example…
…<link rel=”canonical” href=”http://www.limelightdigital.co.uk/seo-services/” /> would go in the header of every page that has similar content to that main page.
This could be: http://www.limelightdigital.co.uk/seo-services&sort=pricedesc which is a page that sorts the services by descending price.
Exactly the same content, but we clearly only want the main seo-services pages being crawled, indexed and receiving the SEO benefits from Google.
Canonical Tag Best Practices
There’s several ways to canonicalise multiple URLs asides from the rel=canonical tag itself.
Some are best practice and have UX / SEO benefits whereas others may cause your site more harm than good.
Each method has a reason behind it and deciding which one to go for should depend on the particular situation.
- 301 Redirect - You’ve probably heard about 301 Redirects before and may well have implemented a few of them on your website pages. All these are is a status code that redirects users from page A to B without them ever seeing page A. This is unlike Canonical tags which don’t redirect users at all and the two seperate pages still exist. 301 redirects are useful for when you don’t want any user to see a certain page but want to maintain any SEO value it holds.
- URL Parameters in Google Search Console - Can’t deal with the stress of implementing individual canonicals on thousands of pages? Web devs taking ages to implement your request? Then simply login to Search Console and exclude them from being crawled. Once signed in simply head over to Crawl>URL Parameters and then add the parameter you wish to exclude e.g. utm_source. This will stop any URL with utm_source from being indexed and causing any duplicate content issues.

Not recommended:
- Block Google from crawling - You’re solving the duplicate content issue but creating a new one by potentially losing any SEO value that your now blocked page may have had!
- Blocking indexing of non canonical versions - So you’ve listened to our advice above and decided you’d let Google crawl but not index the non canonical page. Well unfortunately this just throws up the same problem as before.
- 30X redirects - Any 30 redirect that isn’t 301 is simply not best practice. A 301 redirect passes 90-99% of link juice to the new page whereas the other methods aren’t so useful from an SEo perspective.
- 404 the non-canonical version - Again, with a 404 you’re losing all the ranking signals that the previous page may have gathered by deleting the page. It’s also not great for UX.
When to canonicalise URLs
- When content is extremely similar or duplicate
- If content is serving the same searcher intent
- If you’re updating content
- Content is expiring e.g. old product
Hopefully this article has answered a few questions you may have had surrounding canonical tags and their usage. If you have any questions or if you think we’ve missed anything out please let us know in the comments below.
While you’re here, why not check out our blog for more Digital Marketing insights?